The Cabinet Office recently worked with Automated Intelligence to deliver its Data Remediation and Migration Project.
Automated Intelligence specialises in helping government departments harness their unstructured data. The Cabinet Office used the firm’s cloud-based data analytics and migration solution, AI.DATALIFT, to locate, retrieve and appraise its records, allowing it to address its “digital heap” by automatically recommending content that should be kept or deleted.
At the heart of projects such as this is discerning what is ‘good’ and what is ‘bad’ data – what is useful or not? The problem is exacerbated by the explosion in data generated globally. By 2025, it’s projected that there’ll be 181 zettabytes of data in inexistence.
At the same time, lots of organisations want to get insights from their unstructured data, and so tend to keep hold of it. However, Paul Hudson, chief strategy officer at Automated Intelligence, noted that they often don’t realise the risks that come with their growing expanse of data. “The longer you have it, you don’t know what’s in it,” he said.
David Canning, head of digital knowledge & information management & departmental records officer, Cabinet Office, used the analogy of a library with no index system or even shelves – just boxes full of loose leaf paper. Every day a truck appears and offloads a new load of boxes into the library and all the librarians can do is try to keep up, while the library users become increasingly frustrated as they can’t find what they’re looking for.
“The picture I’ve just painted for you is the situation in virtually every government department,” said Canning. “It certainly was a situation in the cabinet office about four years ago before we started to fix it.”
If you liked this content…
 Q&A: Automated Intelligence talks harnessing data in government
Q&A: Automated Intelligence talks harnessing data in government Harnessing the data explosion for public good
Harnessing the data explosion for public good Blueprint for Modern Digital Government: Breaking down barriers in public service delivery
Blueprint for Modern Digital Government: Breaking down barriers in public service delivery UK Cabinet Office seeks to streamline processes
UK Cabinet Office seeks to streamline processes Automated Intelligence’s View on Think Data for Government: Key Take Aways
Automated Intelligence’s View on Think Data for Government: Key Take Aways
Speaking at the recent Think Data for Government event, Canning explained the process to tackle its big data problem.
“When we think about the library analogy, we need to organise. We need to create some system. We need to get this thing under control. We need to introduce some lifecycle management. We need to identify the stuff that’s redundant, outdated, and trivial. We need to compile the loose leaves into records so that they linked together, and we can catalogue them, we can index, and we can make sense of this. That’s where we are now in many places.”
Introducing an algorithm
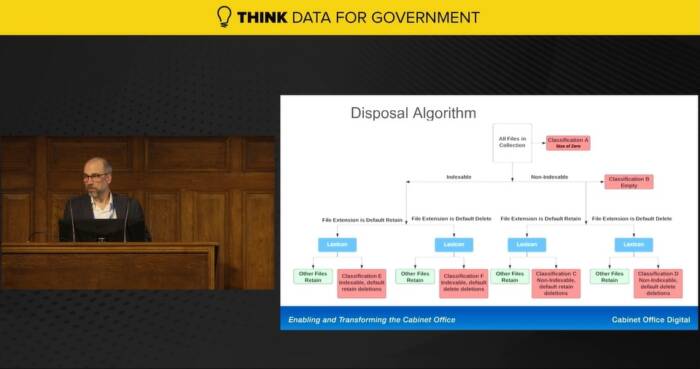
The Cabinet Office recorded 630 million data objects in 2021-2022, including files, emails, databases, and data in spreadsheets, However, when it introduced control systems, that number dropped. It introduced a methodology for disposal which put all the data through a set of decision layers. However, the organisation was still left with an overwhelming volume of files that would simply take a human too long to read and process. It therefore “turned the decision making process of a human being into an algorithm,” explained Canning.
“We’re now using this algorithm (pictured) across all of our datasets to keep control of our data systems. We’ve created essentially an end-to-end digital service, which starts at the point of creation and tracks and classifies information all the way through the lifecycle, all the way to where it enters a digital archive or a digital dustbin.
“This is where we want to be. This is organisation. This is an accessible knowledge base. And it’s organised, and importantly, it’s available. It’s accessible, and it’s understandable. And we can therefore be accountable.”
If you didn’t get a chance to attend the conference live, you can still register and hear the session in full, along with all the other recorded sessions. Please register here.